Basic Copr build process / Architecture diagram¶
Here is the architecture diagram explained on “how the build process goes in Copr”. Each box represents a separate component (separate service, and typically even a separate virtual machine/hostname).
Note
Don’t get confused with the typical Backend and Frontend separation. In our case, Frontend is a management service (n.b. having it’s own backend/frontend logic!) and Backend is the executing service, respecting Frontend’s wishes. The naming is a bit unfortunate, but at this project stage it isn’t an easy thing to change.
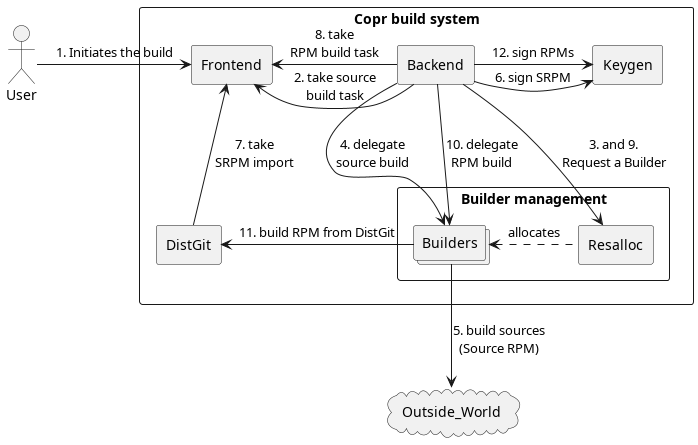
The User can be just a normal (human) user, Bot, or some CI system.
The [Frontend] component is a database with a web-server, handling task queues and providing the web-UI and API for Users.
The [Backend] executes the tasks from [Frontend], and operates the heavy-lifting work (not done by itself, but [Builders]). [Backend] also currently hosts all the built results (RPM repositories).
The optional [Keygen] service holds all the GPG key-pairs for our users, and is able to sign RPMs in their name (upon request, without exposing the private key).
The [DistGit] part is just a “proxy” source storage. Obtaining sources for an RPM build is often an expensive task (if sources are not just uploaded and pre-processed, it may any script doing git clone, with a chain of bit sub-modulees, Autotools automation, tarball downloads, etc.). Therefore we leave the “heavy load” (sources) with [DistGit] and we can later re-use them economically (we neither want to DoS the source code providers by our builders). DistGit is also a center of the build reproducibility (we have a complete package build specification there).
The farm of [[Builders]] is our horsepower. It is a dynamically allocated
set of (ephemeral, individually expendable) machines being able to do what
[Backend] says. The allocation mechanism abstraction is implemented in the
[Resalloc] service. The [[Builders]] set is highly heterogeneous.
It contains machines from different clouds (or hypervisors), having different
power or architectures. The machines (or said just resources) have specific
tags depending on what they can do (and [Backend] can take an appropriate
[Builder] taking a ticket from [Resalloc] with appropriate tag set
(consider self-explaining tag set example architecture_x86_64 and
osuosl_datacenter).
By Outside World we mean any potential source code provider, be that forges (GitHub, GitLab, Pagure), DistGit instances (like Fedora or CentOS DistGit), or even other Copr instances (.. or even the Copr itself).
The (build) process flow of the diagram is explained here:
Using Web-UI or API, a new build is requested. This action generates a build task in [Frontend’s] database. Typical source task specification says where to get sources, and how to process them.
[Backend] polls the task queue, and transforms it into its own priority queue. Then, depending on the current system quota (How many resources are given to a particular user, group, project, … right now? How many
s390xmachines can be taken right now?, etc.) a source RPM task is taken, and a Worker process is started in the background.The Worker process takes a [Resalloc] ticket, asking for a builder machine to perform the build on it.
Over a ssh connection, Worker runs the build on the remote [Buidler] machine (delegates).
The [Buidler] remote process, per job specification, just downloads and processes the sources (
copr-buildercomponent). Generates a source RPM (this could be changed to just tarball or just a set of files). Now, upon a successfully waiting till the builder process finishes, Worker is ready to (a) collect the sources and (b) release the worker (closing the [Resalloc] ticket).The Worker requests a signature. This is done with
obs-signdclient/server so we don’t handover potentially large RPMs. At this point, [Backend] finishes the task by reporting it’s status back to the [Frontend]. As a result of this action (if the sources were correctly built into an SRPM) a new task is generated by [Frontend] — an SRPM import task.[DistGit], similarly to [Backend], polling on task list downloads the source RPM and “caches” the sources in it’s own database. [DistGit] reports the import task status back to [Frontend]. Now, if imported successfully, this action results in an “RPM build task” explosion (one for each selected build root, like
fedora-rawhide-x86_64,epel-8-x86_64, etc.).[Backend] (again according to its priorities) takes the task from the queue and spawns a background Worker for it (note that multiple Workers are being started concurrently, even though we concentrate on one of them to easily explain the process).
The [Backend] Worker requests an appropriate builder machine again, now what typically matters is the builder architecture (e.g. using the
arch_x86_64[Resalloc] ticket for thex86_64chroot job).The Worker executes the build on the Builder (again, over SSH).
Builder (
copr-builderlogic) now downloads the source RPM sources from the Copr-local proxy/cache [DistGit]. This is quick (as said above), we have the sources cached there (and very close, the same lab). So even multiple Builders can do fast source downloads. Taking the sources, it produces a binary RPM (or set of RPM binaries). Buidler process ends, which also ends the Worker’s waiting, so (a) the RPM build results can be downloaded to backend’s result directory and (b) the Builder can be returned back to the cluster.Having the RPMs, Worker on [Backend] can request [Keygen] to sign the RPMs. If successful, Worker places the RPMs into an RPM repository (running
createrepo_c) so the User can consume it (dnf copr enable <project>). Then Worker reports the status back to Frontend. This closes the build flow through Copr.